12 Mag

Nel lontano 2010, in Chorally, eravamo soliti discutere di Intelligenza Artificiale davanti alla macchinetta del caffè. No, non siamo così cool come può sembrare e non siamo stati di certo i primi a parlarne; tuttavia eravamo molto sicuri che quelle due paroline avrebbero aperto le porte di una nuova era.
L’intelligenza artificiale (IA), come conferma una recente analisi condotta da Gartner, sta vivendo infatti un boom senza precedenti.
Parleremo di aziende, machine learning e linked data con Gabriele Antonelli di SpazioDati. Leggi la nostra intervista e ascolta il podcast su Radio Activa!
Intelligenza Artificiale e Machine Learning
Nel sondaggio di Gartner, citato precedentemente, e condotto su più di 3.000 CIO, (responsabili informatici aziendali), gli intervistati hanno classificato l’analisi dei dati e la business intelligence come le principali tecnologie di differenziazione per le loro organizzazioni. Il che confermerebbe le stime di Deloitte, secondo le quali la spesa per l’intelligenza artificiale e il machine learning raggiungerà i 57,6 miliardi di dollari entro il 2021.
Mentre alcune aziende stanno correndo per non perdere questo entusiasmante treno, in molti si chiedono ancora in cosa consista il machine learning o perché sia importante.
L’apprendimento automatico (noto anche come machine learning) è una branca dell’intelligenza artificiale che utilizza metodi statistici per migliorare progressivamente la performance di un algoritmo nell’identificare pattern nei dati.
Nell’informatica, l’apprendimento automatico è una variante alla programmazione tradizionale nella quale si predispone in una macchina l’abilità di apprendere qualcosa dai dati in maniera autonoma. Beh, il classico – e anche il più facile – esempio che si può fare per spiegare il machine learning è quello del cane e del gatto: ad esempio come fa Google a individuare correttamente le immagini degli animali?
“Innanzitutto raccogliamo una notevole quantità di esempi di foto con l’etichetta “cane” (grazie Internet!). Raccogliamo anche un ingente numero di foto con l’etichetta “gatto” e moltissime altre che non elencherò qui. Il computer cerca quindi schemi di pixel e schemi di colori che possano essere utili per ipotizzare se si tratta di un gatto o di un cane (o di qualcos’altro). In un primo momento formula semplicemente ipotesi casuali in merito a quali schemi potrebbero essere validi per individuare i cani. In seguito osserva un esempio di immagine di un cane e valuta se gli schemi correnti sono adeguati. Se per errore scambia un cane per un gatto, apporta alcuni piccoli aggiustamenti agli schemi utilizzati. Successivamente osserva l’immagine di un gatto e ritocca ancora gli schemi per cercare di ottenere quello giusto. Questa procedura viene ripetuta un miliardo di volte; viene osservato un esempio e, se il risultato non è quello sperato, lo schema utilizzato viene ritoccato per migliorare i risultati su quell’esempio.”
Maya Gupta, scienziata ricercatrice di Google
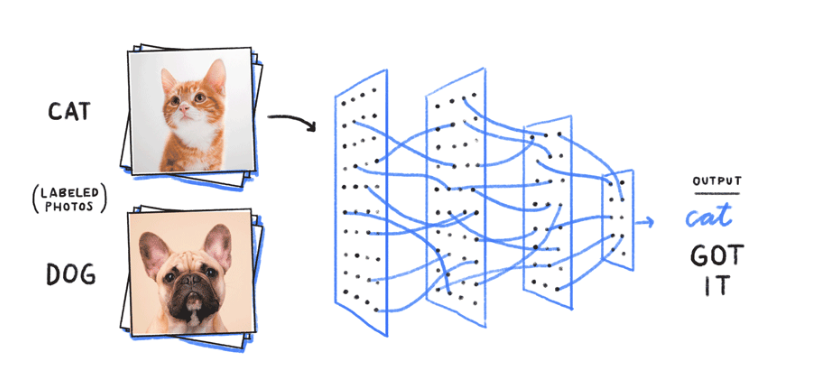
Quegli schemi formano un modello di machine learning, una rete neurale profonda in grado di identificare correttamente cani, gatti e molto altro.
Machine Learning: da Netflix, Google, Spotify
La magia del machine learning è data dal fatto che le aziende la utilizzano in applicazioni che la rendono “trasparente”, in modo da lasciare l’utente finale ignaro di cosa ci sia dietro. Pensiamo ad esempio a Netflix o Spotify.
Spotify crea playlist in base ai gusti musicali degli ascoltatori e lo fa grazie a un algoritmo che si basa su tre diversi sistemi: Collaborative Filtering, Natural Language Processing, e Raw Audio.

- Il Collaborative Filtering permette di combinare i dati in enormi matrici di Python in cui ci sono utenti e tracce: sono queste operazioni matriciali a trovare le corrispondenze e le affinità.
- Il Natural Processing Language (che ha a che fare con il machine learning) serve per sondare siti e blog e per capire cosa si sta dicendo riguardo a dei brani specifici. Ogni termine legato a un brano viene analizzato e gli viene dato un “peso”: maggiore è numero di hyperlinks, references e “belle parole” e maggiore è il rapporto di raccomandazioni di una traccia.
- Il Raw Audio utilizza le reti neurali per creare delle features per ogni traccia che viene caricata su Spotify. A differenza del NPL, dà la possibilità alle tracce sconosciute di essere scoperte.
Ascolta questa canzone composta con l’IA, puoi ascoltarla nel nostro podcast con altre canzoni selezionate da Mark Bartucca!
Intervista a Gabriele Antonelli di Spaziodati
Sono passati 20 anni da quando Tim Berners-Lee nominò per la prima volta il web semantico, gettando così le basi per la tecnologia dei linked data (LD). L’obiettivo era quello di passare da strumento di distribuzione di informazioni prodotte per essere utilizzate da esseri umani ad ambiente in cui le informazioni sono interpretate e consumate direttamente dalle macchine.
Vediamo cosa è successo nel frattempo con Gabriele Antonelli, fondatore di SpazioDati, azienda più all’avanguardia nel panorama italiano nel settore Big Data, Machine Learning e Semantic Web.

Come SpazioDati avete vissuto l’implementazione enterprise, quindi b2b, e siete stati i pionieri in Italia a vendere l’IA Saas, Software as a services. Sono state sfide non da poco per un paese come l’Italia…
Quando abbiamo lanciato, svariati anni fa, il nostro primo prodotto, che permette di estrarre conoscenza da contenuto non strutturato, quindi prevalentemente da testo, ci siamo resi conto, velocemente, che il mercato non era pronto. Era il 2013, e non si era pronti né a livello mondiale né a livello italiano. Siamo riusciti ad ogni modo a posizionarci.
Certo, la difficoltà maggiore, è che SpazioDati non vende IA ma vende un’applicazione dell’IA…
Esatto, vendiamo un prodotto che per l’utente è nascosto. Questo in sintesi mette a disposizione informazioni tradizionali, come quella sulla conoscenza di imprese e persone legata al business, quindi tecnicamente informazioni commerciali, arricchite da dati che noi estraiamo da fonti non strutturate: web, social e news. E per farlo usiamo l’IA in tutta una serie di processi e attività, ma tutto questo al cliente finale è sostanzialmente ignoto.
Nonostante ci sia un grande bisogno di IA, molte aziende italiane non stanno sfruttando a pieno le possibilità date dal machine learning.
È vero, anzi questa riflessione la estenderei in maniera più ampia all’utilizzo delle nuove tecnologie. Sicuramente molte aziende si stanno domandando come migliorare prodotti e processi utilizzando IA, ma spesso hanno poca cultura per introdurre questi tipo di approcci. Purtroppo negli anni si è venuto a creare un gap tra l’Italia e gli altri paesi, europei ed extraeuropei, dovuto spesso alle scarse nozioni e dotazioni di tecnologie delle regioni italiane.
…Anche il sistema italiano potrebbe però sfruttare meglio le innovazioni delle startup.
Se pensiamo essenzialmente alle realtà italiane, oggi a causa di investimenti precedenti e solchi di sviluppo, non hanno la capacità e il coraggio di fare un’innovazione che davvero conti, cosa che invece una startup o una piccola azienda può fare con una certa libertà.
In questo senso le aziende potrebbero comportarsi da incubatori di startup?
Sì, esatto.
Sono quasi vent’anni, e forse di più, che si parla di dati connessi e web semantico, ma c’è un divario significativo tra i dati disponibili e le applicazioni che dovrebbero consumarli. Secondo te per quale ragione?
Qual è il problema del dato? Richiede uno spettro di competenze e capacità variegato. Per rendere un dato fruibile, prima di tutto, bisogna capire cosa vuol dire fruibile. Si può rendere disponibile un dato in maniera raw, perché dall’altra parte hai qualcuno che è capace di montarlo insieme ad altri, e questa è una possibilità. Se, però, si vuole scalare verticalmente e offrirlo a un pubblico più ampio, e quindi non solo al Data Engineer, allora il problema che ti si pone davanti è differente, ed è questo l’elemento che crea il gap a cui ti riferivi nella domanda (un gap che si allarga sempre di più). In questo caso, per prendere dei dati e renderli fruibili hai bisogno di qualcuno che all’inizio li “pulisca”, perché non sono immediatamente utilizzabili. Qualcuno che riesca a montarli insieme; che capisca la semantica del dato (ovvero che sappia cosa significa quel dato combinato con un altro) e che poi riesca a costruire anche dei modelli di Intelligenza Artificiale che valorizzino ancora di più il dato. Qualcuno, da ultimo, ma non è affatto banale, che sia in grado di visualizzarli in maniera intelligibile, comprensibile e facile da usare, altrimenti tutti i passaggi precedenti diventano inutili. Ovviamente, dall’inizio alla fine, serve anche una figura che abbia una visione complessiva di tutti i passaggi.
Quali cambiamenti che vedi nel futuro dei linked data?
Il trend è abbastanza chiaro: ci sarà una maggiore integrazione e valorizzazione del dato attraverso l’utilizzo dell’Intelligenza Artificiale. Oggi siamo all’inizio, ma prevediamo una crescita esponenziale. Si porranno, poi, una serie di quesiti etici sul come utilizzare i modelli algoritmici, perché gli stessi non permettono di capire i nessi causali. Da una parte, quindi, la strada è già tracciata. Dall’altra, ritengo che tutti gli operatori dovranno necessariamente porsi per tempo anche tematiche di natura etica su come utilizzare correttamente la combinazione di dati e algoritmi. Non molto tempo fa è uscito un White Paper della Commissione Ue che, appunto, mette l’accento anche su tematiche etiche per quanto riguarda l’Intelligenza Artificiale…
Ascolta per intero l’intervista a Gabriele Antonelli e le canzoni selezionate da Mark Bartucca su Radio Activa!
